
Expressive robot motion positively impacts human-robot interaction by improving user engagement, likability, or task performance. We present a novel approach to automatically generate and modulate complex, expressive full-body gesture sequences from a multimodal (text, audio, video) context description. Based on a unified mathematical implementation of the Principles of Animation using Dynamic Movement Primitives, we use multimodal foundation models to generate such sequences along with parametric motion variations that are highly context-aware. This method extends the state of the art in terms of flexibility and generality by being interpretable, composable, and working across different robot morphologies. Moreover, we integrate the system into a continuous control framework and leverage knowledge distillation to learn a much smaller model, significantly improving token efficiency and system latency. Results from a user study with a human-like platform indicate that participants judged our system’s motions to be better aligned with the interaction context than motions produced under a non-modulated or API-level motion behavior condition. We also demonstrate how the system can be used to generate expressive motion for robots with different kinematics, showcasing its versatility.
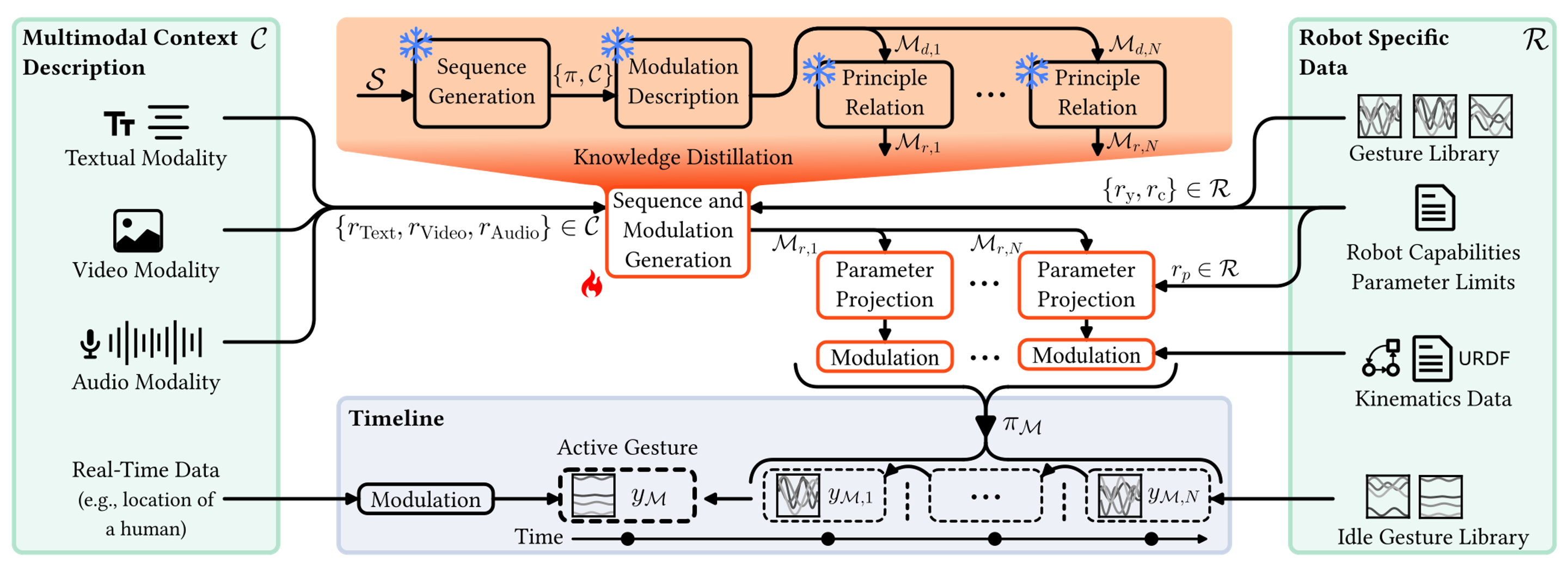
Our method generates and modules expressive motion behavior for robots based on inputs from multiple context description modalities and a specification of robot data. The motion is excuted based on a timeline of individual primitives.
Multimodal context descriptions can be provided with text, video and audio modalities. The modalities must be interpretable by foundation models, which extract relevant contextual features. Additionally real-time data from the robots sensors or external sources can be provided as a basis for continuous modulation. Besides the context, the method requires a specification of robot data. This includes a library of motion primitives, that are learned with Dynamic Movement Primitives, as well as the robots capabilities and kinematics, which bound and guide the modulation of the motion.
The inference for the generation and modulation is trained with knowledge distillation based on a multi-stage teacher pipeline. The systems reasoning is based on a high level sequence generation and a low level modulation generation. With the call results the individual motion primitives are modulated with parameters that are projected to the provided robots capabilities. The distilled foundation model offers significantly improved inference times which are crucial for the system reactivity.
The timeline coordinates the execution of the infividual motion primitives. It ensures smooth transitions between the primitives as well as continuous operation. It also enables modulation during execution to adapt to real-time changes in the context (e.g. gaze tracking a moving person).
Textual modality: "A person approaches and greets the robot, then asks for directions and an explanation. The robot knows that the destination is to its left. The robot's energy level is very low."
Video modality: The image of a person who appears happy. Audio modality: A person saying "[Hi! It’s amazing to see you. It’s been so long]. Textual modality: "Person recognition module: Right camera detected a person, well known, last seen 7 months ago. Microphone: recorded audio."
Textual modality: "A person walks past the robot. The person is busy and in a hurry."
Audio modality: The sound of a person "[knocking]" on a door. Textual modality: "The robot is engaged in a discussion with a person. It is also anticipating the arrival of a second person. An open door is located to the left."
Generated motion behavior for the context: "A person familiar to the robot approaches from its right side. The robot hasn’t seen this person in a long time, and the person is clearly excited to meet the robot again."
@inproceedings{hielscher2026context,
title={Context-Aware Generation and Modulation of Expressive Motion Behavior using Multimodal Foundation Models},
author={Hielscher, Till and Scaparro, Fabio and Arras, Kai O},
booktitle={Proceedings of the 21st ACM/IEEE International Conference on Human-Robot Interaction},
pages={438--446},
year={2026}
}